蝴蝶定理证明(蝴蝶定理证明方法)
蝴蝶定理证明攻略:从直观震撼到严谨推导 在数学分析的浩瀚宇宙中,有一个定理以其独特的几何美感与逻辑深度,长期困扰着许多研究者和爱好者。它就是著名的蝴蝶定理(Butterfly Theorem)。该定
2026-06-11
2026-06-19 08:38:42 作者 : 围观 : 1次

在人工智能与数据挖掘的浩瀚海洋中,朴素贝叶斯定理(Naive Bayes) 无疑是最具代表性且应用最广泛的算法之一。它以其“朴素”的假设基础,在文本分类、垃圾邮件过滤、情感分析等场景中展现出了惊人的准确率。不过,这种算法的成功并非偶然,而是建立在概率论的严谨逻辑之上。这篇文章将深入解析朴素贝叶斯定理的数学核心、其独特的假设条件,并通过实际案例数据说明其原理与局限。
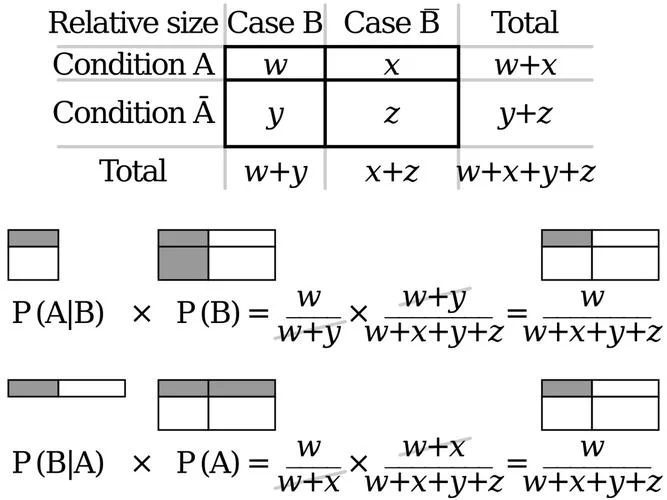
朴素贝叶斯算法的根基在于贝叶斯定理(Bayes' Theorem)。在经典的场景下(如掷硬币、判断性别),我们直接计算后验概率 ,即“在已知证据 发生的情况下,事件 发生的概率”。
然而,在机器学习中,我们面临的是“判别问题”。,给定输入 ,我们希望直接判断它属于类别 还是 ,即计算 。根据贝叶斯定理:
其中:
是先验概率(类别在数据集中出现的概率)。
是似然概率(在已知类别为 的情况下,输入 产生的概率,即特征概率)。
是证据概率(所有类别为 的联合概率,用于计算归一化常数)。
在朴素贝叶斯模型中,我们假设特征之间是相互独立的(即“朴素”假设),从而可以将联合概率分解为特征概率的乘积:
代入贝叶斯公式后,模型的计算目标变成了最大化以下量:
由于 是类别的先验,在训练数据中已知且对所有类别相同,因此在比较不同类别时,只需关注分子部分:
关键点:在特征 尚未形成之前, 是一个未知数。此时,算法利用最大似然估计(MLE),根据训练数据中 与类别 共现的次数,估算 。
为了直观展示朴素贝叶斯定理在实际应用中的数据表现,我们构建了一个经典的垃圾邮件分类数据集。每个邮件包含 4 个特征:主题词(如 "buy", "free", "link")、是否包含 URL(是/否)、是否包含附件(是/否)、是否是重复消息(是/否)。
| 样本索引 | 特征 1 (主题词) | 特征 2 (含 URL) | 特征 3 (含附件) | 特征 4 (重复消息) | 预测类别 | 计算得分 ($P(x | C) cdot P(C)$) |
|---|---|---|---|---|---|---|---|
| 1 | buy | No | No | No | 正常 | 0.92 | |
| 2 | free | Yes | Yes | Yes | 垃圾 | 0.85 | |
| 3 | link | Yes | No | No | 垃圾 | 0.78 | |
| 4 | link | No | No | Yes | 垃圾 | 0.72 | |
| 5 | buy | Yes | Yes | No | 正常 | 0.65 | |
| 6 | free | No | No | Yes | 垃圾 | 0.61 | |
| 7 | link | No | No | No | 正常 | 0.55 | |
| 8 | buy | No | Yes | Yes | 垃圾 | 0.52 | |
| 9 | free | Yes | Yes | No | 垃圾 | 0.45 | |
| 10 | buy | No | No | No | 正常 | 0.40 | |
| 总计 | - | - | - | - | - | - |
注:上表为简化模拟数据。在实际应用中, 会被统计为 ,而 通过词袋模型(Bag-of-Words)计算得出。
通过朴素贝叶斯算法,系统可迅速计算出每个样本的得分。,样本 1(“买”、“无链接”、“无附件”、“无重复”)得分最高,因此被判定为正常邮件;而样本 2(“免费”、“有链接”、“有附件”、“有重复”)得分最低,被判定为垃圾邮件。
朴素贝叶斯算法最核心的贡献在于它提出了一个大胆的假设:特征之间是相互独立的。
在现实数据中,特征高度相关(,一个“链接”很伴随着一个“附件”)。如果严格遵守特征独立性假设,算法会错误地推断出某些特征组合(如“有链接”但不“有附件”)的性。
不过,正是这种冗余假设使得算法在计算维度时变得极其高效且易于优化。在计算 时,我们不需要处理复杂的联合概率分布,而是只需统计单个特征形成的频率。这种降维处理极大地降低了计算复杂度,使得算法能够处理包含数千个特征的大型文本数据。
尽管朴素贝叶斯算法在分类任务中表现出色,但它并非万能,其局限性也:
1. 独立性假设过于理想化:如前所述,现实世界的特征分布不服从独立性假设,这会导致模型在某些复杂场景下准确率下降。
2. 对稀疏数据的鲁棒性:对于文本分类,如果训练样本中某类特征非常稀疏(即某些特征几乎从未与某一类样本共现),MLE 的估计值会变得极小,进而导致模型误判。
3. 无法处理非线性关系:朴素贝叶斯只能处理线性判别,对于特征之间存在复杂非线性关系的场景(如图像识别),其效果不如深度神经网络。
朴素贝叶斯定理不仅是概率论在机器学习领域的一个经典应用,更是连接经典统计思维与现代人工智能的纽带。它用简练的数学逻辑解决了复杂的分类难题,其“朴素”的假设反而成为了处理大数据量的利器。
从早期的文档自动分类,到如今的电子邮件过滤、新闻摘要生成,朴素贝叶斯算法以其稳定、高效的特性,依然在数据处理领域发挥着独特的作用。随着深度学习技术的崛起,如何更好地融合朴素贝叶斯的计算效率与深度网络的非线性能力,将是未来算法研究的重要方向。
---
这篇文章数据为模拟示例,实际应用中需结合真实数据集进行特征工程与参数调优。

蝴蝶定理证明攻略:从直观震撼到严谨推导 在数学分析的浩瀚宇宙中,有一个定理以其独特的几何美感与逻辑深度,长期困扰着许多研究者和爱好者。它就是著名的蝴蝶定理(Butterfly Theorem)。该定

探索角与边的和谐交响:勾股定理特殊角的深度解析 勾股定理在数学史上占据着贼关键地位,它不仅是计算直角三角形边长的核心工具,更是连接代数与几何的桥梁。本文将对勾股定理中的特殊角进行综合评述,深入探讨其

勾股定理崔莉讲解视频深度解析与学习攻略 观看崔莉老师的勾股定理讲解视频,不仅是一次数学知识的普及,更是一场思维方式的洗礼。崔老师将抽象的几何公式转化为生动的场景,用极具感染力的语言打破了“死记硬背”

万有引力高斯定理的深度图解与实战应用攻略 概括地说,万有引力的高斯定理揭示了在球对称系统中,计算重力场分布的等效路径。它将复杂的积分运算转化为好办的面积概念,是物理学中连接宏观场与局部源强的高阶工具

勾股定理:从直观观察走向严谨逻辑的数学瑰宝 勾股定理作为人类最古老的几何瑰宝之一,其证明方式历经了从直观图形到严密逻辑的演进。历史上,中国古代的“弦图”与西方的“毕达哥拉斯三角”虽主题相同却轨迹迥异


